
| CARGO: BB-architecture robot controller for Evolutionary Computation with a simulator of LEGO robot |
|
| CARGO: BB-architecture robot controller for Evolutionary Computation with a simulator of LEGO robot |
This page informs about the progress with research done as part of Pavel's thesis work.
In the autumn 2000, the task with single robot was specified as follows:
A robot is equipped with two light sensors on the bottom (to safely navigate along a line) and one heading upwards (to detect lamp), obstacle avoidance-bumpers in front (hopefully on side won't be neccessary if the robot won't change position while turning). It is placed in a closed world with obstacles. There is an overhead light at some location and the black line drawn on the bottom surface starting bellow this light leads to cargo loading station. The same holds for cargo unloading station, but its light is turned off in the beginning. After loading the cargo, the light for loading is turned off and the light for unloading is turned on. After the cargo is unload, the loading light is turn on again, unloading light is turned off and the whole procedure repeats.
The complex task for the robot will be as follows:
In this project, I will incrementally evolve this relatively complex behavior using several different approaches, compare, and perhaps analyze the comparison.
I will use a message-passing agent-based architecture (i.e. controller built of modules that run in parallel and communicate by sending asynchronous messages). Modules have access to sensors and arriving IR messages if they wish. Each actuator is controlled by its associated module (driver), one driver can serve more actuators. Drivers collect and sort-out the messages received from all the other modules and translate them into low-level hardware signals for the actuators. I believe the overhead caused by drivers will be acceptable also for LEGO embedded computer.
Individual modules will possibly have different internal architectures. They can be handcoded, evolved recurrent networks, GPs, FSMs, RLs, other learners (perhaps Bayes...), etc. Their interfaces with other modules (i.e. what outputs will form messages sent where) can again be evolved, handcoded, or learned.
The hierarchy (if any) inside of this distributed controller will be from completely handcoded to completely emergent.
Each agent(module) has a message queue where the messages are queued if it is a parallel process. Otherwise it can execute the action immediatelly. Message is delivered to an agent by calling its message method. Messages have priority [not yet part of the model]. Message method can be called by two processes at the same time, so it is written in a reentrant-safe way.
First, I will construct the controllers in simulation with keeping in mind that the same code will run on LEGO embedded computer. In practical experiments, I would take the evolved controllers to tune them on real robots. The robots will be able to learn on-line, but I will deliberately avoid on-line evolution with testing each individual of each generation on a real robot. I believe this ER approach can be advantageous in those types of tasks where, for example, robot had experienced some damage and its actuators and sensors don't work as they should. In such a case, ER can generate very low-level behaviors like moving forward, or simple movement operations, which can safe the mission of such a robot. I believe that in most of the other cases, i.e. when the sensors and actuators of the robot perform as expected, the controller can be designed in simulation once the actuatory and sensory control of the robot is understood.
Remark: During evolution, the controllers will be tested against several different environments in each evaluation to assure generalization.
This outline leads to planning of the work on this project. First I will implement a simulator, which will compute the fitness of the individuals. This simulator will work with continuous environments with noise. I will try to use behavioral fitness function where possible (i.e. not functional; in the above task, robot will be rewarded for finding the line, loading the cargo, finding the line again and unloading the cargo.) I will have to consider a small fitness penalty for pushing into walls (first the signal comes to the touch sensor and the robot has some time to react before getting the penalty. Basically the obstacles are solid and heavy, so the robot can push, but it won't get anywhere, thus the penalty is not so important. After the simulator is developed, I will test in on simple hand-coded controllers also with LEGO robots. In the next stage, the simulator will be plugged into a GA package, most likely modified/extended GALib, or self-made code. Next step will be tuning the system for the above experiment and testing the hypotheses formulated for the thesis, specifically, that
If the time allows, the setup will be modified for another task, which will include a group of heterogenous robots equipped with different sensors. Namely, in a group of 3 robots, one robot will be able to lift and transport objects, another robot will be able to carry mobile camera that will trasmit the video signal to steering centre, which can generate advices for the group, and the third robot will be able to modify the environment in certain ways - for example push objects that stand in the way, push buttons, emit light or sound to control the active scene built with help of LEGO construction sets.
In the first version, the controller will contain the following handcoded modules with the following messages:
navigate
fwd n start moving n small steps forward, next received message aborts
right n start turning right n small steps, next message aborts
left n start turning left n small steps, next message aborts
turnrnd start turning in random direction random number of steps (up to 180 deg.)
idea is to use this for env. exploration
stop stop moving
fast switch robot to a fast speed mode
slow switch robot to a slow speed mode
cargo
load to load cargo when at cargo loading station
unload to unload cargo when at cargo unloading station
linefollower
follow n will start following line at most n small steps, if
the line is detected
linefollower works with lower priority than navigate
MotorDriver:
receives messages: POWER N where N can be -255 to 255, 0 means break
and immediatelly sets the new power to the motor
Avoidance
drives robot forward until hits obstacle, then turns random, uses the module Navigate
for details, see modules.h.
The first evolutionary experiments will evolve a FSM, which on its state transitions will generate up to one of the above commands. If the time will allow, this might be compared to a recursive neural network.
As an alternative representation (more interesting), I would not provide the above modules. Instead, modules would consist of randomly initialized recurrent neural networks. In adition there would be a relatively simple control policy that would activate these networks (possibly another network or fsm) - also part of the genome. ( The problem with this approach I have is that the task is probably a bit difficult for this 'from-the-scratch' controller, and I am not very convinced that the behaviors like forward and followline should be evolved, when they are easy to implement. Even though it is very tempting to try.)
The complex task described above will be evolved incrementally. I will compare the following incremental scenarios:
ORIGINAL, SEQUENTIAL INCREMENTAL STAGES
The simulator is written and being debugged. It is implemented for UNIX systems with a viewer that displays the progress of simulation in a graphical window:
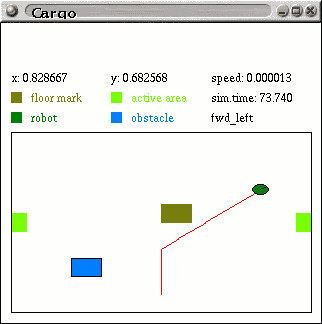
The environment is specified in a project file. It can contain obstacles, marks on the floor of different color, overhead lights, active areas, which can trigger execution of scripts, and time events that can be periodically repeated. Robot location, dimension and other parameters can be also configured.
Modules communicate using asynchronous or synchronous message passing and run in parallel (implemented with POSIX threads).
Here is a high-level sketch of SIMULATOR/CONTROLLER interface
single robot case:
CONTROLLER -> actuators -> SIMULATOR <-> ENVIRONMENT
<- sensors <- | ^
| |
fitness v | control.prog.to run
EA
The current tasks are listed here
Relatively recent version is here. Warning: it is not even alpha, still in development.
to get a working directory with the latest version of the project, run
$ cvs checkout eval/cargoNow you can compile the system:
$ cd eval/cargo $ makeNow you can modify the files. When you are ready to submit a new version to CVS repository, use the following commands (in the directory where are the modified files):
$ cvs update $ cvs commitThe first will display the files that were modified. It will also update the files, if your version is older than the newest version in the repository (that can happen only if someone else commited the same file while you were editting it. In such case, be careful, because the changes might be merged automatically - you have to make sure that the program still works before running the commit command. Anyway, your changes will not be discarded automatically). The second command will automatically start an editor, where you will write a description of what you have done (and mainly why you have done it) and then it will save the new versions to the repository.
If you added some files, they will not be added automatically. You have to run the command:
$ cvs add filename $ cvs commitfirst. Similarly, if you have deleted some files, they will not be deleted automatically, you have to run:
$ cvs remove filename $ cvs commitFinally, to get info about a history of a particular file, run:
$ cvs log filenameand to see the differences between two revisions of the same file, run:
$ cvs diff -c -r one_revision -r another_revision filename
For more detailed instructions, see the manuals at CVSHome.
You need a ssh client (almost sure you have one), Then you just need to set up environment variables as follows:
CVSROOT=:ext:your_user_name@dionysus.idi.ntnu.no:/root/cvsroot CVS_RSH=the_path_to_sshThe best is probably to put a the following at the end of your ~/.bash_profile:
export CVSROOT=:ext:your_user_name@dionysus.idi.ntnu.no:/root/cvsroot export CVS_RSH=the_path_to_sshThen you can use the cvs as described above.
Please send your comments, ideas, questions, bug-reports to Pavel.